




Data is the cornerstone upon which all machine learning (ML) models are trained. Even the most sophisticated ML algorithms cannot overcome poorly curated datasets! In this blog, we will briefly describe some of the most important factors that influence the performance of a model and explain how you can make your own data “ML-ready” with an easy to follow check-list.
Data can be described by its three main characteristics: quality, quantity, and diversity. Each of these characteristics can have a major impact on the predictive performance of a model. Carefully considering and curating your dataset at the outset of a project can save you considerable time and money, and improve your overall AI-accelerated experience.
Quality
Quality refers to the error, relevance, consistency, and completeness of your data.
Error
Model performance is inherently limited by the error of the data. There are two kinds of error: epistemic and aleatoric.
- Epistemic error comes from a lack of knowledge or incomplete information, and can be reduced by gathering more data. This would be an error like sampling bias, where an insufficiently large sample size doesn’t fully capture the distribution. Collecting more samples would reduce this error.
- Aleatoric error comes from the inherent randomness in measurements and cannot be reduced. This includes instrument or measurement variation, operator variation, or material variation. For example, if you have a thermometer that measures +/- 2 °C, then in the absolute best case scenario your model will only be able to predict values within +/- 2 °C accurately. Collecting repeat measurements on control samples is a useful way to estimate the aleatoric error, which will help you understand the limitations of your data collection process and can help you set realistic expectations for model performance and improvement.
Error is an unavoidable part of experimentation, and it isn’t always possible to control. Nevertheless, awareness of error can help you consider the best way to design experiments, collect the most informative data, and understand the level of performance that you can expect from ML model predictions.
Relevance
Relevance refers to data that truly captures the properties or features that you want to model. The impact of data relevance cannot be understated. Failing to include relevant properties or including the wrong properties will reduce the ability for your model to predict effectively.
For example, if you know that the way a formulation is prepared changes its final performance, it is crucial to include this information. Consider a scenario where you have two identical formulations that were prepared using two different methods. In Table 1, exclusion of the preparation method means that the model cannot discern between these two data points. We see that in Table 2, inclusion of the preparation method will assist the model in learning that preparation affects performance. However, inclusion of irrelevant data can distract a model from learning what is important, potentially picking up on spurious correlations. These are relationships between variables that are not causally related, and tend to be introduced by some systematic process. For example if a specific test always happens at a particular facility that just so happens to have a specific condition. In Table 3, the model may also come to the conclusion that the facility or light condition is an important parameter for achieving high performance.

Expert intuition can also help guide which parameters are relevant to include. In our Table 3 example, an expert may know that this chemical reaction is not photosensitive, meaning that the lamp color is irrelevant. This is an oversimplified example for the purposes of pedagogy, but serves to illustrate the importance of feature relevance. In reality, including too many parameters is not often a problem, as unnecessary or irrelevant parameters will also be removed during the feature selection stage of model training.
Consistency
Datasets with inconsistent labels and formatting are a fundamental challenge faced by the entire data science community. Data cleaning is typically one of the first steps taken, because formatting errors can prevent machine interpretability, halting you from even loading up and viewing data in the first place. Exploratory data analysis, or the act of plotting your data to get a sense of what it looks like before building an ML model, is a common practice among data scientists, and requires at minimum a dataset that is formatted properly.
Furthermore, inconsistency in data can lead to confusion in the model, reducing its predictive performance. If you are using data from multiple sources, check that units are the same within each category and that variables are named consistently across all datasets. Exploratory data analysis can often catch these inconsistencies, as the data scientist may notice extreme outliers caused by improper unit conversions and the like. Finally, inconsistencies in naming can often be especially challenging to resolve for anyone except for the domain expert who collected the data.
A common data problem that lies at the intersection of Relevance and Consistency is the implicit rather than explicit labeling of data. How your data is encoded affects the model's ability to interpret and weigh its importance. Something we have commonly encountered is the embedding of relevant information in sample names. Inclusion of relevant data is not enough if it is not machine interpretable.

Fortunately, NobleAI offers advanced data screening methods to help with any of these points of concern. We have developed custom tools for data extraction, manipulation, and structuring, helping you to jump start your AI-accelerated journey that much faster.
Completeness
While ML models can overcome incomplete datasets to learn the underlying trends in data, missing dependent variables may reduce the performance of your model. Incomplete datasets can be especially detrimental for landscapes that are not continuous and smooth, because models may over- or under-fit in regions with missing data.
In the Table 6 example, we have a dataset with missing values. We can easily see that temperature and stress tolerance are linearly correlated, so in this case it would be relatively easy for the model to learn the trend regardless of the missing 30 °C stress tolerance value. However, the trend in cleaning performance is less clear, and the missing 20 °C value would be challenging for the model to infer the distribution without more surrounding data.

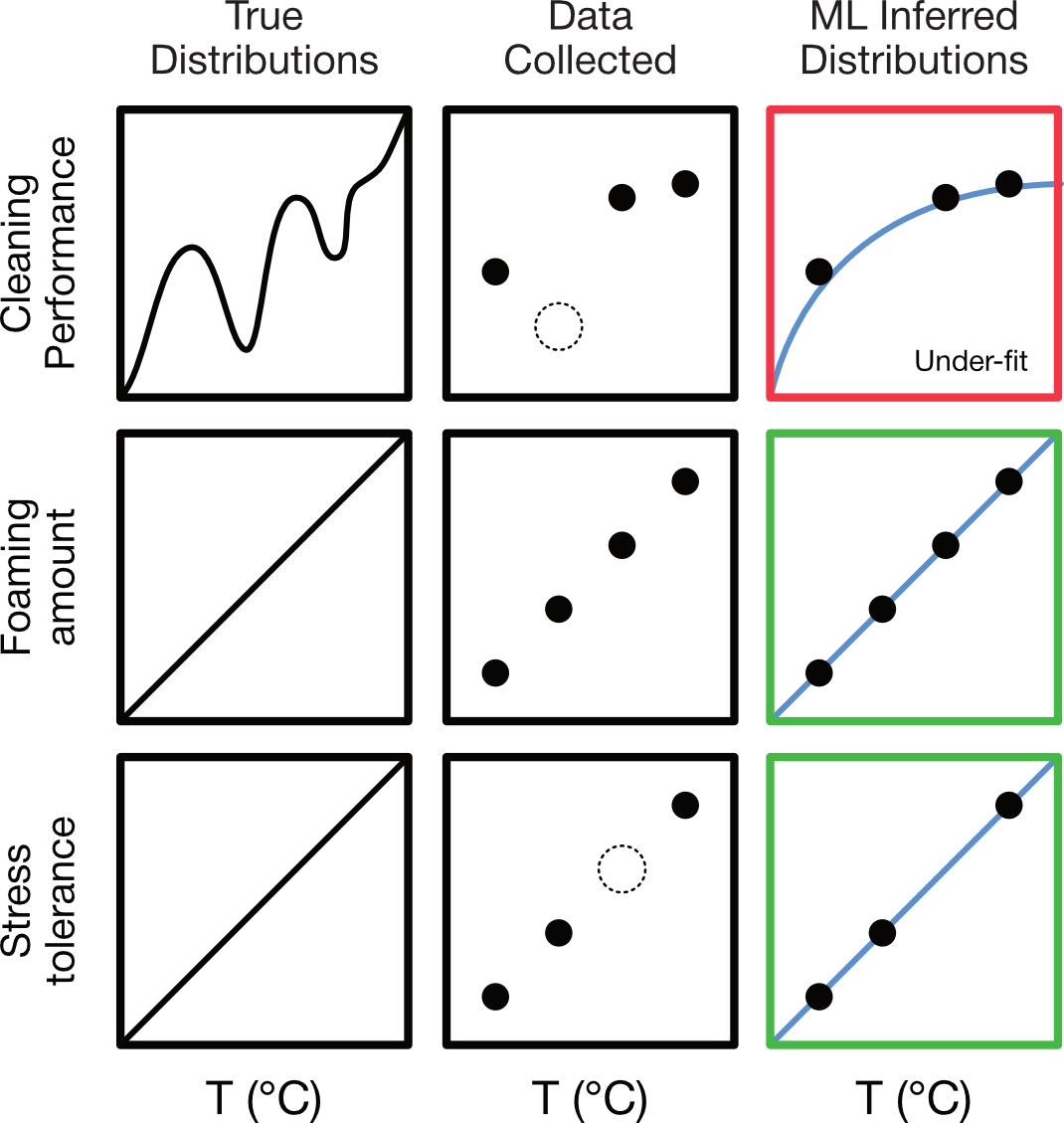
The extent to which your model is challenged by gaps depends on the specific dataset at hand and is inextricably tied to the quantity and diversity of data available and the complexity of what you are trying to model. In reality, the ‘true distributions’ aren’t available beforehand, so it is difficult to know the extent to which missing values would impact the model's performance. Nevertheless, missing or incomplete data is not uncommon in ML and can be worked around, though it may become clear after the initial modeling stage that additional data needs to be collected to refine your model.
Quantity
Quantity refers to the amount of data that you provide a model. This includes the number of independent observations and the number of independent and dependent variables per observation. The amount of data needed depends on the complexity of your problem and type of model that is used. (Conversely, the type of model can be selected based on data size limitations to accommodate small datasets.)
Diversity
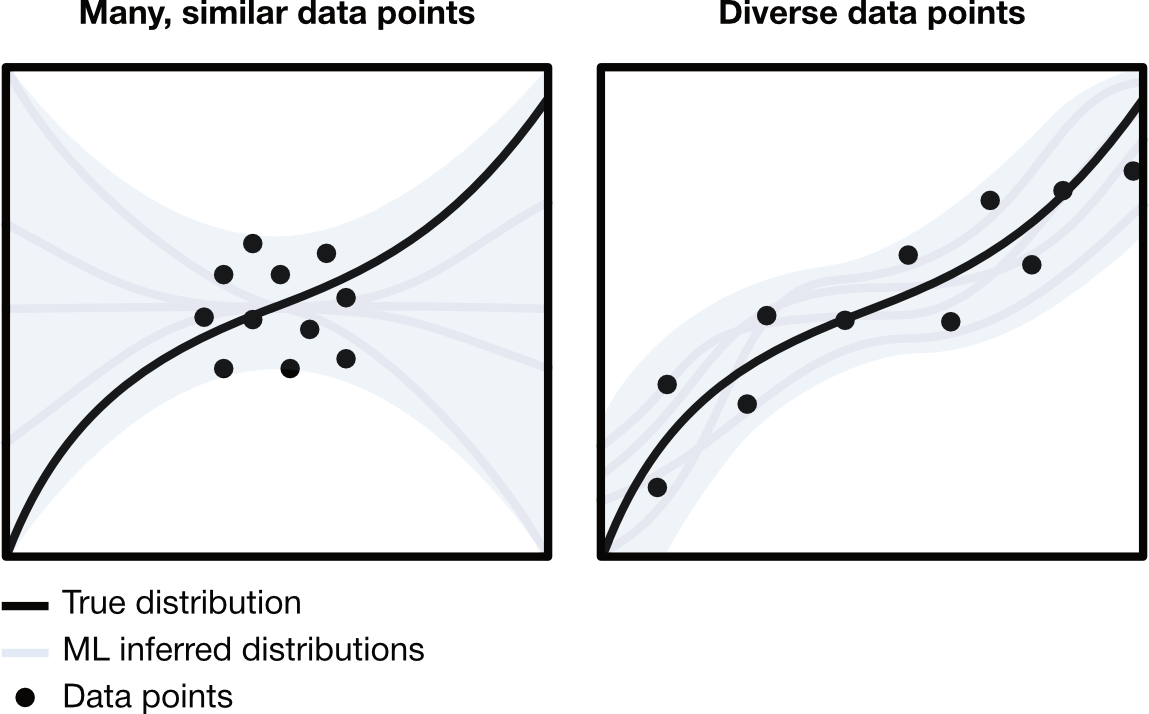
Once quality considerations are addressed, diversity of your dataset is the most important to unlocking powerful, generalizable, and extensible models. More data does not necessarily mean better predictions, but more diverse data can. Many similar data points may prevent a model from learning the true distribution of your data, while many diverse data points allow the model to learn relationships and trends in the space between observations, improving its ability to find an accurate function to describe the data and improves the interpolative/extrapolative power of the model to predict beyond what it has seen.
ML models benefit from the inclusion of ‘failed experiments’ in the training set. (Note that this does not mean untrustworthy data, we mean experiments where the results were not the desired outcome.) This is because if a model is only trained on ‘successful’ results, it will not be able to predict even the most obvious of failures.
Prioritizing curation efforts
Well defined datasets take time and effort to create, but are paramount to the success of an ML project. We also understand that in a fast-paced environment, you may not have the time or resources to spend on making the ‘perfect’ dataset. Some considerations should be prioritized over others because they can have a larger impact on the outcome of your project. When it comes time to train a model, a smaller, well curated, complete dataset is preferable to a bigger, messy, incomplete dataset. This is because at the end of the day, machine interpretability is the final hurdle that must be satisfied for an ML model to be built. All the data in the world is useless if the model can’t understand what it is looking at.
You may be asking, how much data do I need then? How messy is too messy? There is no one-size-fits-all answer, but the good news is that at NobleAI, we are ready to help you get your data in ship-shape. That ‘large, messy, incomplete dataset’? It can be cleaned! Though we are here to guide you through the process of data preparation, we hope that these considerations help you understand what is necessary to create an “ML-ready” dataset, and equip you with the language and tools to discuss and strategize your project effectively.
Final Note: Iteration for Acceleration
We discussed what to do when you have too much data, but what happens if you don’t have enough? Data collection and experimentation can be expensive, and it can be difficult to know a priori what data would be the most informative to train an ML model. Or, as is often the case, your data was not collected for the express intent of ML. This is the reality for many companies and may lead you to believe that your data is not machine learnable. But this is not the case!
As we mentioned before, you do not need the ‘perfect’ dataset to begin using ML. In fact, ML is well suited in an iterative research cycle alongside laboratory experimentation (standard or automated) to enhance model quality and expedite product development. Models can be used for design of experiments (DOE) to suggest maximally informative data to collect. As the models suggest new formulations to test and data is collected, you can re-train models to update them with the new information. By integrating ML into your experimental process, you can hone in on more performant formulations quicker and more effectively.
Checklist for ML-Ready Data Preparation
- Define your desired outcome. This will help you focus your data curation efforts.
- What is the outcome that you want to predict?
- What are the independent and dependent variables?
- How will this outcome make an impact on your business?
- Set realistic expectations for the data curation stage. How data has been archived is highly variable from company to company, and some require more time and effort than others to sort and organize.
- Work with a NobleAI representative and subject matter experts at your company to decide which variables are most relevant to include.
- Collect your files and organize them in a coherent and consistent fashion.
- NobleAI provides standardized dataframe templates to help assist you
- NobleAI can also help extract and format data.
Frequently Asked Questions
Data is the cornerstone upon which all machine learning (ML) models are trained. Even the most sophisticated ML algorithms cannot overcome poorly curated datasets! In this blog, we will briefly describe some of the most important factors that influence the performance of a model and explain how you can make your own data “ML-ready” with an easy to follow check-list.
Data can be described by its three main characteristics: quality, quantity, and diversity. Each of these characteristics can have a major impact on the predictive performance of a model. Carefully considering and curating your dataset at the outset of a project can save you considerable time and money, and improve your overall AI-accelerated experience.
Quality
Quality refers to the error, relevance, consistency, and completeness of your data.
Error
Model performance is inherently limited by the error of the data. There are two kinds of error: epistemic and aleatoric.
- Epistemic error comes from a lack of knowledge or incomplete information, and can be reduced by gathering more data. This would be an error like sampling bias, where an insufficiently large sample size doesn’t fully capture the distribution. Collecting more samples would reduce this error.
- Aleatoric error comes from the inherent randomness in measurements and cannot be reduced. This includes instrument or measurement variation, operator variation, or material variation. For example, if you have a thermometer that measures +/- 2 °C, then in the absolute best case scenario your model will only be able to predict values within +/- 2 °C accurately. Collecting repeat measurements on control samples is a useful way to estimate the aleatoric error, which will help you understand the limitations of your data collection process and can help you set realistic expectations for model performance and improvement.
Error is an unavoidable part of experimentation, and it isn’t always possible to control. Nevertheless, awareness of error can help you consider the best way to design experiments, collect the most informative data, and understand the level of performance that you can expect from ML model predictions.
Relevance
Relevance refers to data that truly captures the properties or features that you want to model. The impact of data relevance cannot be understated. Failing to include relevant properties or including the wrong properties will reduce the ability for your model to predict effectively.
For example, if you know that the way a formulation is prepared changes its final performance, it is crucial to include this information. Consider a scenario where you have two identical formulations that were prepared using two different methods. In Table 1, exclusion of the preparation method means that the model cannot discern between these two data points. We see that in Table 2, inclusion of the preparation method will assist the model in learning that preparation affects performance. However, inclusion of irrelevant data can distract a model from learning what is important, potentially picking up on spurious correlations. These are relationships between variables that are not causally related, and tend to be introduced by some systematic process. For example if a specific test always happens at a particular facility that just so happens to have a specific condition. In Table 3, the model may also come to the conclusion that the facility or light condition is an important parameter for achieving high performance.
Expert intuition can also help guide which parameters are relevant to include. In our Table 3 example, an expert may know that this chemical reaction is not photosensitive, meaning that the lamp color is irrelevant. This is an oversimplified example for the purposes of pedagogy, but serves to illustrate the importance of feature relevance. In reality, including too many parameters is not often a problem, as unnecessary or irrelevant parameters will also be removed during the feature selection stage of model training.
Consistency
Datasets with inconsistent labels and formatting are a fundamental challenge faced by the entire data science community. Data cleaning is typically one of the first steps taken, because formatting errors can prevent machine interpretability, halting you from even loading up and viewing data in the first place. Exploratory data analysis, or the act of plotting your data to get a sense of what it looks like before building an ML model, is a common practice among data scientists, and requires at minimum a dataset that is formatted properly.
Furthermore, inconsistency in data can lead to confusion in the model, reducing its predictive performance. If you are using data from multiple sources, check that units are the same within each category and that variables are named consistently across all datasets. Exploratory data analysis can often catch these inconsistencies, as the data scientist may notice extreme outliers caused by improper unit conversions and the like. Finally, inconsistencies in naming can often be especially challenging to resolve for anyone except for the domain expert who collected the data.
A common data problem that lies at the intersection of Relevance and Consistency is the implicit rather than explicit labeling of data. How your data is encoded affects the model's ability to interpret and weigh its importance. Something we have commonly encountered is the embedding of relevant information in sample names. Inclusion of relevant data is not enough if it is not machine interpretable.
Fortunately, NobleAI offers advanced data screening methods to help with any of these points of concern. We have developed custom tools for data extraction, manipulation, and structuring, helping you to jump start your AI-accelerated journey that much faster.
Completeness
While ML models can overcome incomplete datasets to learn the underlying trends in data, missing dependent variables may reduce the performance of your model. Incomplete datasets can be especially detrimental for landscapes that are not continuous and smooth, because models may over- or under-fit in regions with missing data.
In the Table 6 example, we have a dataset with missing values. We can easily see that temperature and stress tolerance are linearly correlated, so in this case it would be relatively easy for the model to learn the trend regardless of the missing 30 °C stress tolerance value. However, the trend in cleaning performance is less clear, and the missing 20 °C value would be challenging for the model to infer the distribution without more surrounding data.
The extent to which your model is challenged by gaps depends on the specific dataset at hand and is inextricably tied to the quantity and diversity of data available and the complexity of what you are trying to model. In reality, the ‘true distributions’ aren’t available beforehand, so it is difficult to know the extent to which missing values would impact the model's performance. Nevertheless, missing or incomplete data is not uncommon in ML and can be worked around, though it may become clear after the initial modeling stage that additional data needs to be collected to refine your model.
Quantity
Quantity refers to the amount of data that you provide a model. This includes the number of independent observations and the number of independent and dependent variables per observation. The amount of data needed depends on the complexity of your problem and type of model that is used. (Conversely, the type of model can be selected based on data size limitations to accommodate small datasets.)
Diversity
Once quality considerations are addressed, diversity of your dataset is the most important to unlocking powerful, generalizable, and extensible models. More data does not necessarily mean better predictions, but more diverse data can. Many similar data points may prevent a model from learning the true distribution of your data, while many diverse data points allow the model to learn relationships and trends in the space between observations, improving its ability to find an accurate function to describe the data and improves the interpolative/extrapolative power of the model to predict beyond what it has seen.
ML models benefit from the inclusion of ‘failed experiments’ in the training set. (Note that this does not mean untrustworthy data, we mean experiments where the results were not the desired outcome.) This is because if a model is only trained on ‘successful’ results, it will not be able to predict even the most obvious of failures.
Prioritizing curation efforts
Well defined datasets take time and effort to create, but are paramount to the success of an ML project. We also understand that in a fast-paced environment, you may not have the time or resources to spend on making the ‘perfect’ dataset. Some considerations should be prioritized over others because they can have a larger impact on the outcome of your project. When it comes time to train a model, a smaller, well curated, complete dataset is preferable to a bigger, messy, incomplete dataset. This is because at the end of the day, machine interpretability is the final hurdle that must be satisfied for an ML model to be built. All the data in the world is useless if the model can’t understand what it is looking at.
You may be asking, how much data do I need then? How messy is too messy? There is no one-size-fits-all answer, but the good news is that at NobleAI, we are ready to help you get your data in ship-shape. That ‘large, messy, incomplete dataset’? It can be cleaned! Though we are here to guide you through the process of data preparation, we hope that these considerations help you understand what is necessary to create an “ML-ready” dataset, and equip you with the language and tools to discuss and strategize your project effectively.
Final Note: Iteration for Acceleration
We discussed what to do when you have too much data, but what happens if you don’t have enough? Data collection and experimentation can be expensive, and it can be difficult to know a priori what data would be the most informative to train an ML model. Or, as is often the case, your data was not collected for the express intent of ML. This is the reality for many companies and may lead you to believe that your data is not machine learnable. But this is not the case!
As we mentioned before, you do not need the ‘perfect’ dataset to begin using ML. In fact, ML is well suited in an iterative research cycle alongside laboratory experimentation (standard or automated) to enhance model quality and expedite product development. Models can be used for design of experiments (DOE) to suggest maximally informative data to collect. As the models suggest new formulations to test and data is collected, you can re-train models to update them with the new information. By integrating ML into your experimental process, you can hone in on more performant formulations quicker and more effectively.
Checklist for ML-Ready Data Preparation
- Define your desired outcome. This will help you focus your data curation efforts.
- What is the outcome that you want to predict?
- What are the independent and dependent variables?
- How will this outcome make an impact on your business?
- Set realistic expectations for the data curation stage. How data has been archived is highly variable from company to company, and some require more time and effort than others to sort and organize.
- Work with a NobleAI representative and subject matter experts at your company to decide which variables are most relevant to include.
- Collect your files and organize them in a coherent and consistent fashion.
- NobleAI provides standardized dataframe templates to help assist you
- NobleAI can also help extract and format data.


